Text Analytics: Using Survey Comments for Sentiment Analysis
Regional Reserve Banks frequently receive and collect information that is communicated in an unstructured or textual form. The qualitative data conveyed through surveys or gathered at roundtable meetings with business firms or our own Bank directors are very valuable pieces of information for the Banks. However, summarizing and extracting meaning out of this information are very challenging tasks. So how can we make sense out of this information?
Recent development of text analytic techniques could potentially help out. The use of text analytics is becoming widespread in government agencies, academia, and the private sector as a way to uncover some of the information hidden in unstructured and textual resources. This approach has its limitations, of course.
As with any other method, it is subject to bias and misinterpretation, and the results should always be contrasted against other methods and data. However, the analysis of qualitative data may help enhance the predictive accuracy and reduce the "noise" embedded in other more traditional sources of information currently available.
What can text analytics do?
Broadly speaking, text analytics can be used in several ways. For instance, it can be applied to find hidden connections, patterns, and models in plain-language narratives or unstructured data. It might be useful to detect emerging areas of concern or interest in specific target groups. Alternatively, it could be used to find trending themes by identifying topic areas that are either novel or are growing in importance.
Some specific applications of text analytics include sentiment analysis, text clustering (i.e., classification and grouping of documents according to similarity measures), content categorization (assigning text documents into predefined categories and building models), concept extraction, entity extraction (identifying named text features, such as people, organizations, places, etc.), entity relation modeling (i.e., learning relations between named entities), and text summarization.
How does text analytics work?
Text analytics methods generally involve four steps. The first step consists of the selection of the input or sources to be analyzed, usually refer to as "corpus." The input can be any textual data, such as open-ended questions in surveys, a collection of documents, or transcribed minutes from a meeting.
The second is a pre-processing step that involves the implementation of several methods and techniques to simplify the data. The process includes the extraction and identification of individual words (usually refer to as "tokenization" of the textual document), the removal of common or "stop" words that do not provide any meaning to the text (e.g., "the," "at," "in," "with"), name and entity recognition, and word stemming and lemmatization.
Stemming is a process through which words are reduced to their roots or stems. For example, the words "fox" and "foxes" may be reduced to the root "fox." Lemmatization also tries to group words, but the process is somewhat more complicated because it attempts to associate words according to their meanings. For example, the lemma of the words "paying," "paid," and "pay" is "pay." The objective of both stemming and lemmatization is basically to match and group words in order to reduce the size of the data and, consequently, reduce processing time and memory.
The third is the analysis step. At this stage, the goal is to extract features from the documents, define a model based on those features, and train the model with a sub-sample of the data.
Lastly, the fourth step consists of the validation of the results from the analysis. The validation should be done both internally, i.e., using available data not employed to construct the model, and externally, i.e., using other available data sources and methods.
Application: Fifth District Survey of Manufacturing Activity
As an illustration, I show here the results of applying very simple text analytic tools to evaluate survey comments from the Fifth District Survey of Manufacturing Activity. The Fifth District Survey of Manufacturing Activity is conducted monthly by the Richmond Fed and collects qualitative information. Survey participants are asked a number of questions in an attempt to capture current and expected business conditions. The responses to the questions are limited to three: "decreased," "no change," or "increased."
For example, participants are asked whether employment, orders, or shipments decreased, did not change, or increased from the previous month, and how they expect those variables to change in the next six months. (For more information about the Fifth District Survey of Manufacturing Activity, refer to the previous Regional Matters post.)
Moreover, the survey allows participants to provide open-ended comments. The goal of the present exercise is to evaluate the tonality of those comments, examine how the sentiment expressed in the comments changes over time, and determine the connection between sentiment and responses of participants to the other questions included in the survey. I focus here on the period that goes from December 2010 to September 2015.
Before analyzing the textual data, I first pre-processed the survey comments following the steps described earlier. Next, I examined all the comments offered by participants at every period and identified words that typically have a negative or positive connotation or express uncertainty. For this exercise, I assigned words or short expressions into one of these three categories based on a predefined dictionary. The frequency of each category is then tabulated. The results of this exercise are summarized in the graph below.
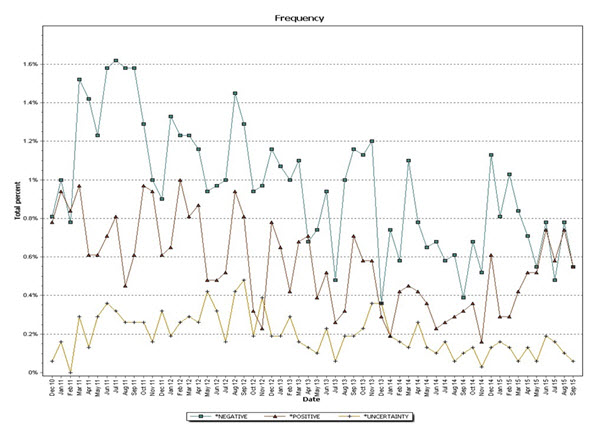
The following observations from the graph are worth pointing out. First, note that the frequency of words that have a negative connotation shows a declining trend until roughly September 2014; however, the trend becomes positive since then. Second, the frequency of words with a positive connotation seems to show a similar behavior. And third, the frequency of words expressing uncertainty seems to show a more volatile behavior: It increases until approximately October 2012, declines until July 2013, rises again reaching a peak in December 2013, and flattens out throughout the rest of the period.
Further analysis is required to determine to extent to which the sentiment embedded in the comments is in fact related to changes in current (or expected) business conditions. To establish such relationships, I compared the tonality of comments to responses to other questions in the survey. Using only the results for the question that asks participants about current changes in employment (similar results are obtained for shipments and orders), the table below shows the percentage of respondents showing a negative, uncertain, or positive sentiment for each of the three possible responses to the question.
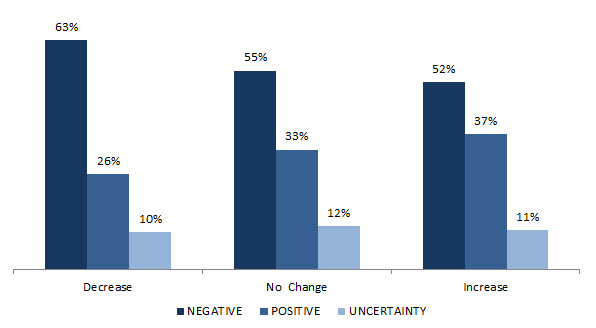
First, note that those who report a decrease in employment also tend to show a higher level of negative sentiment. The negative sentiment is lower for those reporting no change and even lower for those reporting an increase in employment. The level of positive sentiment increases as we move from the category of those who report a decrease in employment to those who report an increase. Finally, there seems to be a high correlation between participants who indicate some degree of uncertainty and those who tend to respond "no change."
Limitations and Caveats
First, it should be noted that not all participants write comments. In fact, on average, only 24 percent of respondents write comments. In general, respondents who write comments also tend to respond more "negatively" to the questions asked in the survey than those who do not write comments. The conclusions obtained from this type of analysis should take into account the fact that perhaps survey participants who tend to write comments may be systematically biased in one direction or the other.
Second, this kind of analysis can be performed to identify, for example, respondents who systematically show a negative, positive, and uncertain sentiment. Third, this is just a first attempt to evaluate the tonality of the comments. A more rigorous analysis is definitely required in order to apply this method for other purposes, such as assessing the level of uncertainty in the economy or drawing conclusions about individuals' expectations. However, the preliminary results seem to indicate that this kind of analysis could be promising.
Have a question or comment about this article? We'd love to hear from you!
Views expressed are those of the authors and do not necessarily reflect those of the Federal Reserve Bank of Richmond or the Federal Reserve System.